
Large language models (LLMs) are advanced artificial intelligence models that use deep learning techniques, particularly a subset of neural networks known as transformers.
Large language model use transformers to perform natural language processing (NLP) tasks like language translation, text classification, sentiment analysis, text generation, and question-answering.
LLMs are trained with a massive amount of datasets from various sources. Their immense size characterizes them – some of the most successful LLMs have hundreds of billions of parameters.
Jump to:
- What is the Importance of Large Language Models?
- How Do Large Language Models Work?
- Types of Large Language Models
- Large Language Model Examples
- What Is the Purpose Behind Large Language Models?
- Bottom Line: Large Language Models
What is the Importance of Large Language Models?
The advancement in artificial intelligence and generative AI is pushing the boundaries of what we once thought of as far-fetched; LLMs are trained on hundreds of billions of parameters and are used to tackle the obstacles of interacting with machines in a human-like manner.
LLMs are beneficial for problem-solving and help businesses with communication-related tasks, as they are used to generate human-like text, making them invaluable for tasks such as text summarization, language translation, content generation, and sentiment analysis.
Large language models bridge the gap between human communication and machine understanding. Aside from the tech industry, LLM applications can also be found in other fields like healthcare and science, where they are used for tasks like gene expression and protein design. DNA language models (genomic or nucleotide language models) can also be used to identify statistical patterns in DNA sequences. LLMs are also used for customer service/support functions like AI chatbots or conversational AI.
Also see: Top Generative AI Apps and Tools
How Do Large Language Models Work?
For a LLM to perform efficiently with precision, it’s first trained on a large volume of data, often referred to as a corpus of data. The LLM is usually trained with both unstructured and structured data before going through the transformer neural network process.
After pre-training on a large corpus of text, the model can be fine-tuned on specific tasks by training it on a smaller dataset related to that task. LLM training is primarily done through unsupervised, semi-supervised, or self-supervised learning.
Large language models are built on deep learning algorithms called transformer neural networks, which learn context and understanding through sequential data analysis.
The concept of the Transformer was introduced in a 2017 paper titled “Attention Is All You Need” by Ashish Vaswani, Noam Shazeer, Niki Parmar, and five other authors. The transformer model uses an encoder-decoder structure; it encodes the input and decodes it to produce an output prediction. The following graphics are from their paper:
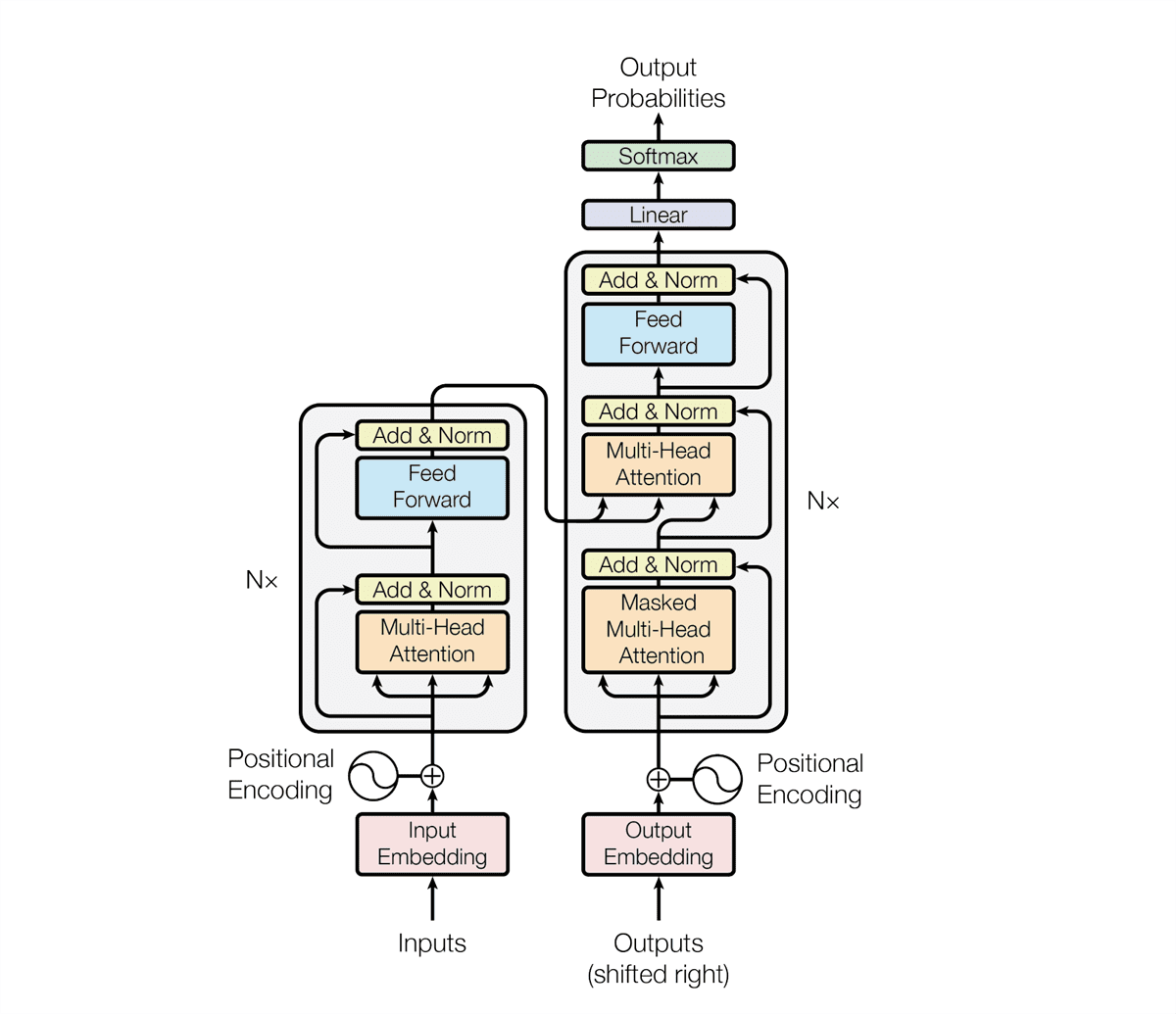
Multi-head self-attention is another key component of the Transformer architecture, and it allows the model to weigh the importance of different tokens in the input when making predictions for a particular token. The “multi-head” aspect allows the model to learn different relationships between tokens at different positions and levels of abstraction.

Also see: Best Artificial Intelligence Software
Types of Large Language Models
The common types of LLMs are as follows:
Language Representation Model
Many NLP applications are built on language representation models (LRM) designed to understand and generate human language. Examples of such models include GPT (Generative Pre-trained Transformer) models, BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa. These models are pre-trained on massive text corpora and can be fine-tuned for specific tasks like text classification and language generation.
Zero-shot Model
Zero-shot models are known for their ability to perform tasks without specific training data. These models can generalize and make predictions or generate text for tasks they have never seen before. GPT-3 is an example of a zero-shot model – it can answer questions, translate languages, and perform various tasks with minimal fine-tuning.
Multimodal Model
LLMs were initially designed for text content. However, multimodal models work with both text and image data. These models are designed to understand and generate content across different modalities. For instance, OpenAI’s CLIP is a multimodal model that can associate text with images and vice versa, making it useful for tasks like image captioning and text-based image retrieval.
Fine-tuned or Domain-specific Models
While pre-trained language representation models are versatile, they may not always perform optimally for specific tasks or domains. Fine-tuned models have undergone additional training on domain-specific data to improve their performance in particular areas. For example, a GPT-3 model could be fine-tuned on medical data to create a domain-specific medical chatbot or assist in medical diagnosis.
Also see: Generative AI Companies: Top 12 Leaders
Large Language Model Examples
You might have heard of GPT – thanks to ChatGPT buzz, a generative AI chatbot launched by Open AI in 2022. Aside from GPT, there are other noteworthy large language models.
- Pathways Language Model (PaLM): PaLM is a 540-billion parameter transformer-based LLM developed by Google AI. As of this writing, PaLM 2 LLM is currently being used for Google’s latest version of Google Bard.
- XLNet: XLNet is an autoregressive Transformer that combines the bidirectional capability of BERT and the autoregressive technology of Transformer-XL to improve the language modeling task. It was developed by Google Brain and Carnegie Mellon University researchers in 2019 and can perform NLP tasks like sentiment analysis and language modeling.
- BERT: Bidirectional Encoder Representations from Transformers is a deep learning-based technique for NLP developed by Google Brain. BERT can be used to filter spam emails and improve the accuracy of the Smart Reply feature.
- Generative pre-trained transformers (GPT): Developed by OpenAI, GPT is one of the best-known large language models. It has undergone different iterations, including GPT-3 and GPT-4. The model can generate text, translate languages and answer your questions in an informative way.
- LLaMA: Large Language Model Meta AI was publicly released in February 2023, with four model sizes: 7, 13, 33, and 65 billion parameters. Meta AI released LLaMA 2 in July 2023, available in three versions, including 7B, 13B, and 70B parameters.
What Is the Purpose Behind Large Language Models?
While LLMs are still under development, they can assist users with various tasks and serve their needs in various fields, including education, healthcare, customer service, and entertainment. Some of the common purposes of LLMs are:
- Language translation
- Code and text generation
- Question answering
- Education and training
- Customer service
- Legal research and analysis
- Scientific research and discovery
Bottom Line: Large Language Models
Large language models represent a transformative leap in artificial intelligence and have revolutionized industries by automating language-related processes.
The versatility and human-like text-generation abilities of large language models are reshaping how we interact with technology, from chatbots and content generation to translation and summarization. However, the deployment of large language models also comes with ethical concerns, such as biases in their training data, potential misuse, and the privacy considerations of their training. Balancing their potential with responsible and sustainable development is essential to harness the benefits of large language models.
Also see: 100+ Top AI Companies 2023